Artificial intelligence is more than just a single initiative. It’s an approach to problem-solving that can drive value for your customers and your business through a broad range of products, features, and services. We’ve talked in prior blogs about making your organization AI-ready and identifying the right problems to focus on. To fully operationalize your AI capability, the final step is to create a durable advantage architecture that makes all your AI projects easier to deliver, more quickly and at enterprise scale.
The diagram below illustrates a closed-loop system designed to enable rapid prototyping, testing, and learning at scale.
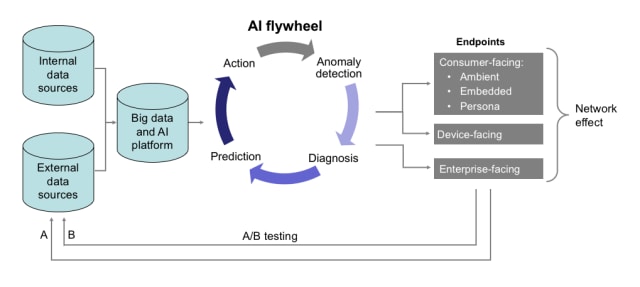
On the left side are your data sources. It’s important to complement the internal data sources available in your company with relevant external data sources; the more data sources you bring together, the better your reasoning will be. Of course, it’s always essential to work within legal and privacy policies.
Moving to the right, your data sources must be ingested into a big data platform. This doesn’t necessarily imply centralization; much of the work I’ve done with my team has involved data and distributed systems beyond our own data centers. For that reason, the ability to access and work with data across third-party environments is a key design requirement for your AI architecture. Third-party data can often be extremely valuable because it can provide a more complete picture of your business and the customers that you serve. Ingesting this data and merging it with your own can be challenging, primarily because it can be difficult to identify the right way to merge the data. Even if merging the data is straightforward ensuring that the resulting data set is stable can be challenging because different partners may operate with different Service Level Agreements (SLAs) or for other reasons. Spending time thinking about the architecture as a whole – and particularly this element – is a critical part of the overall process.
The next step is to provide a mechanism to ingest this data and reason on it. During my tenure at NASA, we developed an AI Flywheel specifically tuned to address system-health management for aircraft, spacecraft, and other complex systems. At Intuit, our AI flywheel is focused on financial applications for consumers, small businesses and self-employed customers. Regardless of domain, this mechanism functions as follows:
- Anomaly detection – As data comes in, the system checks to see whether it fits familiar patterns. If it does, the usual action is taken. If not, the system proceeds to diagnosis.
- Diagnosis – Let’s say that the data is determined to be anomalous. A customer has entered yearly earnings of $100K into their TurboTax application, while the previous year they made $50K. Ideally, the system would automatically determine the root cause of this change based on all of the data observed so far. It may conclude that the anomaly is due to a data entry error. Or, based on the data, it may notice that the customer has changed jobs, and that the new employer and the new job family is consistent with the new data. Reasoning about these types of issues is challenging and can take a combination of domain knowledge, first-party data, third-party data, and ML-based reasoning systems to make this determination. In most cases it is important for the system to generate a confidence score that can be used internally or by the user to help determine whether the diagnosis is actionable.
- Prediction – Depending on the type of issue discovered, in some cases the system may need to make a prediction about the correct value in order to complete the diagnosis. In other cases, however, a prediction may need to be issued that is not due to a particular anomaly but to recommend the best course of action for the customer. Prediction systems are very dependent on data and, depending on the domain, can utilize both rules-based and ML-based models. In some cases, a hybrid approach may be necessary where domain knowledge is combined with ML-based models to make the best predictions.
Depending on the scenario, it may be necessary for the system to automatically take action on the user’s behalf, or it may be necessary to recommend a set of actions that the user could take on their own. This step is highly dependent on the particular scenario and the level of automation that the system offers.
The example above is a simple one of course. The AI flywheel can also address much more complex problems. The ability to detect and diagnose anomalies, make predictions, and take the appropriate actions lets you continually refine the quality and accuracy of the customer experience.
The output produced by the AI flywheel can next be driven to a variety of endpoints, including:
- Consumer-facing endpoints – mobile, web and other endpoints.
- Enterprise-facing endpoints – APIs that other companies use to interact with the systems at your company.
Together, these endpoints, and the ways in which people interact with them, create a network effect that provides valuable opportunities for A/B testing. This allows you to continually refine the quality of the AI flywheel and to tune your algorithms, user experience, workflow, and data usage through a closed-loop system.
The big picture
While the technological considerations I’ve discussed in this blog are a key part of a successful AI capability, it’s important to remember that data architecture, deep learning, natural language processing, and so on are only part of your AI journey, and not necessarily the first or most important part.
To ensure success, it’s critical to think holistically about what’s needed to build AI-powered products that deliver value for your customers and a durable advantage for your business. That process is as much about organizational culture and business strategy as it is about technological innovation. By focusing on all three elements, you can successfully leverage the full potential of AI for your customers.